In one of our previous articles about Swarm we promised to go into more details about how it works, and today we uphold that promise. Let's jump right in!
Why synchronizing history was so challenging
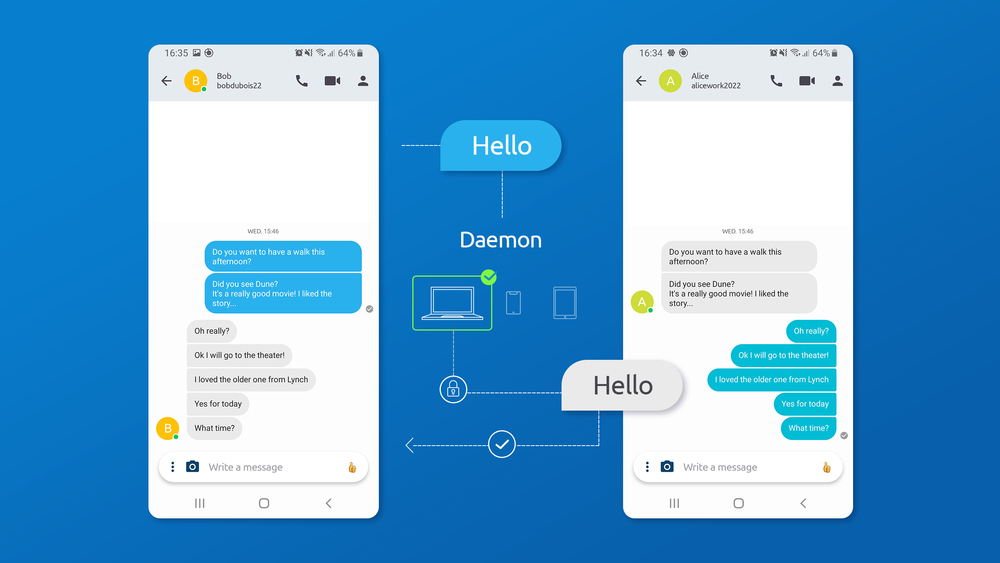
Until recently (before Swarm), when you sent a message to one of your contacts via Jami, Jami would only send the body of the message to your contact, and wait for the confirmation. Basically this is how things worked with non-Swarm conversations:
-
Alice sends "Hello" to Bob;
-
the Jami daemon on Alice's device searches for Bob's connected devices;
-
for each connected device, the message is encrypted with the device's key, and sent via the DHT or a peer to the peer socket; and finally
-
Bob's devices send a confirmation that they received the message, otherwise Alice's device will keep resending the message until either it is received by one of Bob's devices or the cache is invalidated (1 week).
The mechanism was simple, but glossed over a lot of details, making it nearly impossible to synchronize conversation histories and really difficult to scale it up to group conversations. To list a few shortcomings:
-
Because messages were not ordered, they could be received in a different order than they were sent in. But in order to synchronize history, the messages must be ordered. There are various ways to do that, such as using timestamps, incremental ids, structures with parent/child, etc.
-
It was not possible to differentiate between two messages with the same information. If Alice had two devices synchronizing and sent "Hello" from each of the two devices, one could not programmatically tell whether or not they are the same message. This is why messages need to have a (unique) identifier.
-
Because Jami would only send to the recipient contact's devices, it means that if the sender had multiple devices, only the one sending the message would have a copy of the sent message.
-
If one of the recipient contact's devices came online after the message was marked as sent on the sender side, the message delivery would not be retried, and so the newly online device would not receive a copy. Storing what devices received each message would not be optimal, and would be rather hard to maintain.
-
As Jami did not (and does not) rely on any centralized servers, the only timestamp we knew for each message would be the one recorded on the recipient side when we the message was received. Since messages can arrive several hours (or even days) after being originally written on the sender's side (because both peers need to be connected for the message to be delivered) some conversation histories could be weird, with messages appearing out of order and/or appear to be newer than they really are.
This is why we needed a new system for messaging, and to store messages in a better structure, to enable synchronizing messages between many devices in a reasonable way.
How Swarm works
A structure to synchronize
Conversations in a distributed network cannot be considered in a linear fashion. In fact, not all devices may always be online at the same time. And since there are no servers to store the conversations, the devices will have to. So, the best way to imagine a distributed conversation is with a tree data structure, where each device in the conversation has a subpart of this tree. For example:
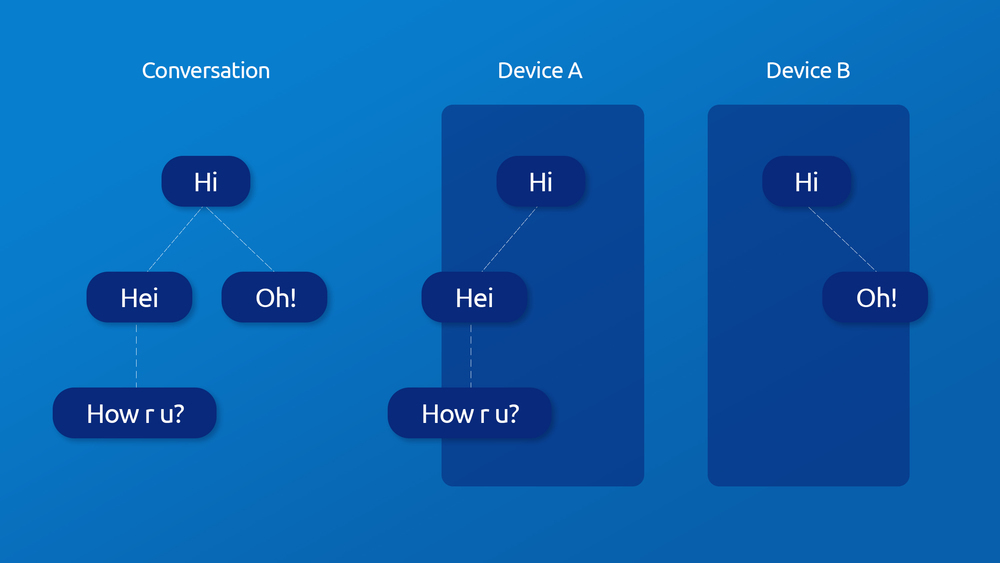
It could be much simpler and more reasonable to synchronize this tree structure across devices, since we could directly synchronize part of the trees and easily identify what parts are missing. Moreover, messages are ordered, because we know the id of the previous message for each message. This kind of structure already exists in the wild, so we wouldn't have to reinvent the wheel, and could use known protocols for that. One of the most used protocols that provides this kind of structure and the ability to synchronize it in a distributed environment is Git, which is already widely used for many different use-cases, using tools such as the libgit2 library, and has many of the features that we would like, such as signing commits with keys. This is why we choose to use git as the foundation for Swarm conversations and storing them. Although using a tree to represent a conversation brings a lot of improvements and enables new possibilities, it does have its own problems.
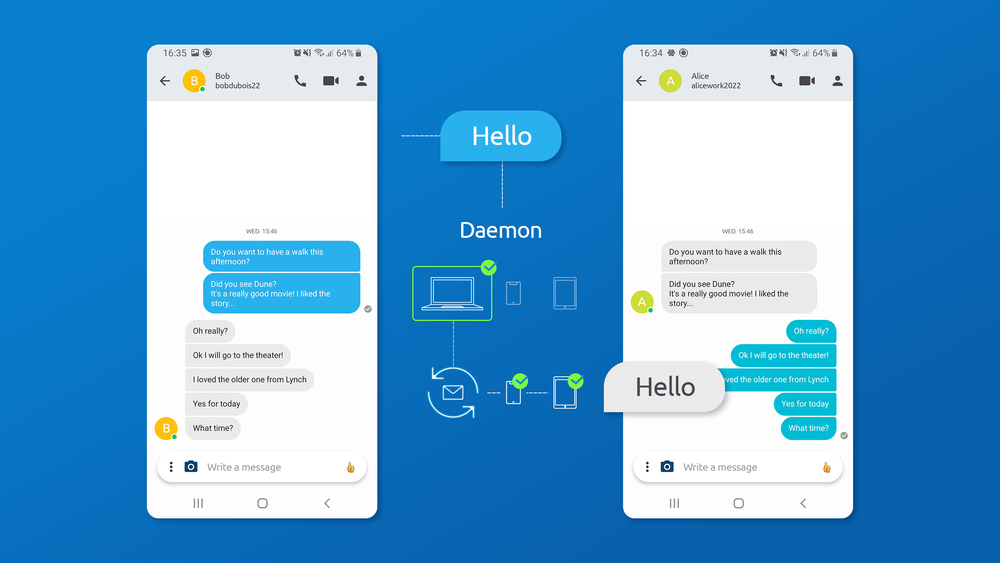
So, with Swarm, this is how a message is sent:
-
Alice sends "Hello" to the conversation with Bob;
-
the Jami daemon on Alice's device will notify online devices about the new message; or if a device comes online, the Jami daemons will establish a peer-to-peer connection and try to fetch any new messages from the other peer respectively and synchronize message history;
-
other devices will retrieve the new message from Alice's device, or any other device that has already received the new message; and
-
messages will be verified and validated, and then shown in the Jami client application.
What is a message?
One way to look at Git would be as a tool based around synchronizing a tree of commits. In part due to this reason we decided to store each message as a commit (rather than, say, a file) in the corresponding git repository for that conversation. We can divide a git commit into three parts:
- the metadata of the commit, such as the author, parent, date, and the signature (which could be used to verify the issuer);
- the commit message, typically used to describe the changes recorded in the commit; and
- a diff (list of differences) of changes to the files in the repository compared to the parent commit.
The two first parts are the most interesting for our use-case of Swarm, and the last one is for the most part not used for Swarm (will explained why later in this article). The commit message can be used to store the messages in the format we want, and the metadata can be used to store information such as who wrote the message. Finally, the signature mechanism in git lets us sign messages with the device's key, and to verify that messages are coming from an authorized peer.
In Jami's Swarm conversations, each message can be of one of the following types (with the possibility of adding more types in the future, if needed): text message, file transfer, call, or member event.
Displaying the history
Displaying a tree of messages is not user friendly. Even with applications that support threads, the history is typically displayed as a linear conversation with links to the parent. So, the tree must be linearized for displaying. However, there are multiple ways to linearize a tree. For example for the following tree:
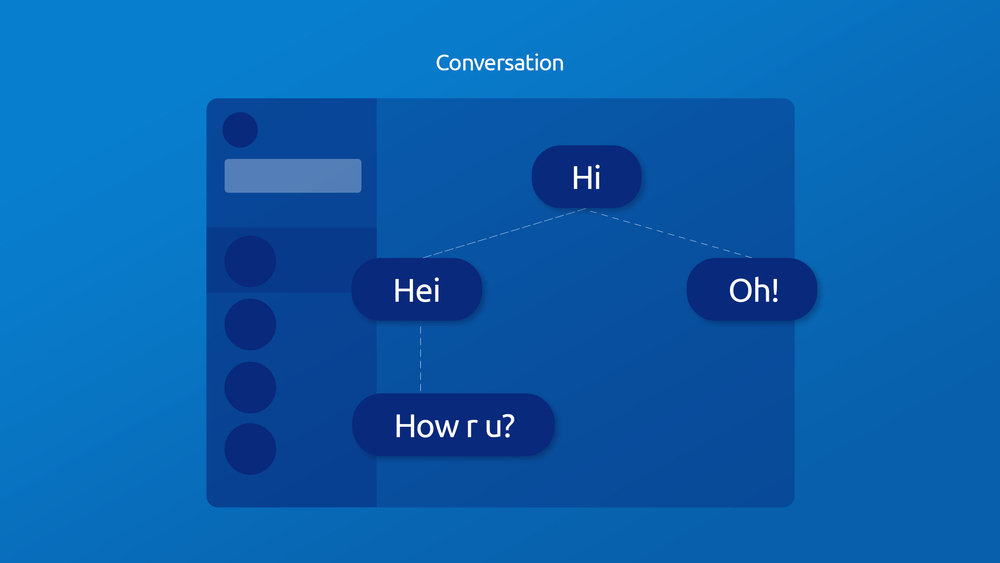
"Hi, Hei, Oh!, How r u?" and "Hi, Oh!, Hei, How r u?" are two valid linearizations, even though the tree here is very simple. Timestamps could be used to organize messages, and it would work most of the time, but in a distributed system, one cannot necessarily trust the time of other devices; it may have been modified and differ with the current device's time, intentionally or not. So, "How r u?, Hi, Hei, Oh!" could be a valid output. That's why we chose to display messages after first sorting them topologically (parents before children), then chronologically by timestamp. This means that even if How r u? has a timestamp older than Hi, it will always be displayed after Hei.
Other messages
Even if a conversation needs a lot of data synchronized across devices, it's not the case for all messages. Some messages will still be ephemeral and exist for a few seconds, typically those that really only make sense for a limited time and in an instantaneous setting, namely: typing indicators, message read status, or location share. More ephemeral message types could be added in the future if need be.
In that case, these ephemeral messages will not appear in the git history of the conversation repository, but will only be sent to those devices in the conversation that are online at that moment.
How about conflicts?
Generally, when using git, multiple people may modify the same files at the same time, resulting in a conflict when synchronizing, which must be resolved. It's clear that we cannot and should not ask everyday Jami users to manually resolve such conflicts in their conversation histories. That's why as we mentioned earlier we almost never use the third part of commits (changed files and their diff) in Swarm git repositories. Conflicts can only arise in the diff part of commits, so we prevent them by storing the conversation messages as commits messages, and very rarely add files in the repository; and in the cases where we really do need to add or modify files, we do it in a careful manner that avoids conflicts or results in conflicts that can be automatically resolved by git.
Will file transfers be synchronized in the repository?
No, not presently, and this is for two reasons. First, as mentioned in the last section, we must avoid any potential conflicts, and adding files would make that significantly harder and more complex if not impossible. Second, Jami must be able to work on devices with low storage capacity, so we will never force a device to receive and store big files if the user does not accept it. We recently refactored and reworked the Jami file transfer system for Swarm, and we plan on publishing a more detailed article about the new file transfer system and how it works with Swarm in the near future.
How to help
Testing features
Some of the Swarm-related features that can now be tested are as follows:
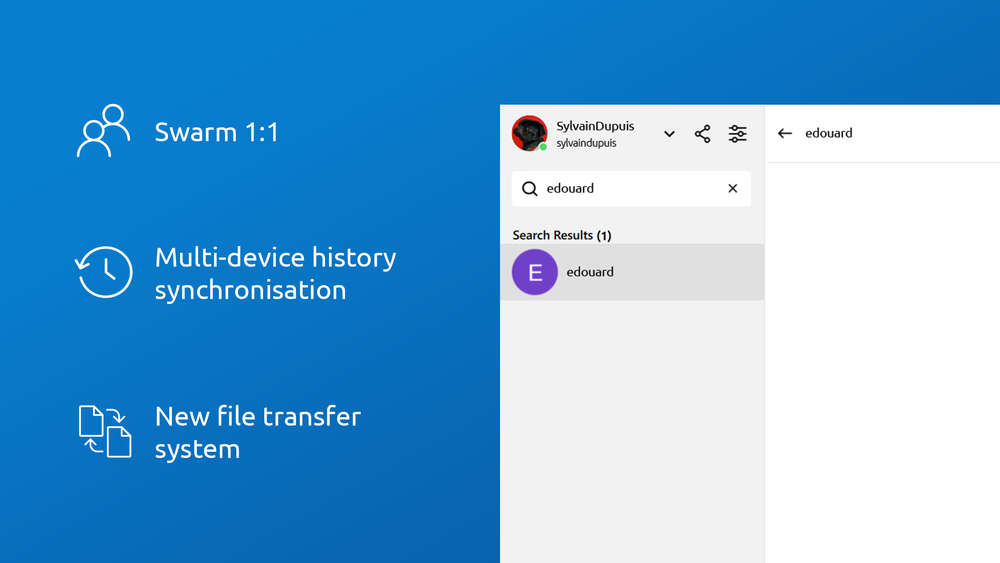
-
1:1 Swarm creation: if you and your contact have a recent version of Jami with Swarm support, a new conversation request should result in a new Swarm conversation being created.
-
Multi-device conversation history synchronization: if you have connected multiple devices to your account, if you send a message in a Swarm conversation from one of your devices, then all of your other devices should receive a copy of it as well, the next time they are online at the same time as the device you sent the message from. As alluded to earlier, your devices do not need to be online all at the same time or at the same time as the device you sent the message from; but rather, any device that has a copy of the message should be able to provide it to the other device(s) if it's online at the same time as the other device(s).
-
New file transfer system.
As seen in recent articles on the Jami blog, there are a lot of new features included in Jami client applications. Additionally, the Qt-based Jami desktop application also has the following abilities:
-
answering a video call using only audio; and
-
changing an audio call into a video call, by sharing the screen or starting the camera.
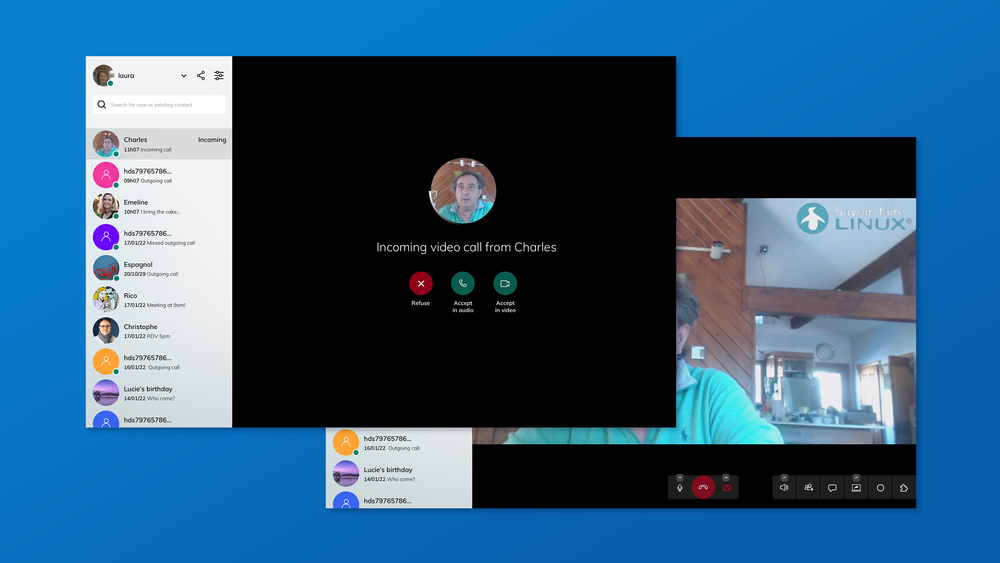
The mobile applications of Jami currently only have partial support for these two features, and work is underway for advancing and improving their implementations.
Replacing the jet engine while still flying
Swarm brings a lot of changes to Jami on how conversation works. This means to use Swarm conversations, both you and your peers need a recent version of Jami. However, we cannot break the compatibility for users in one day or break all conversations. So, if your contact's version of Jami does not support Swarm, nothing should break, and older non-Swarm conversations should continue to work as expected: sending messages, adding a non-Swarm contact, file transfer, and calls must continue to work as of today. Swarm conversations will only be created an used when both peers have new and compatible versions of Jami.
Reporting issues
If you notice or experience any problematic scenarios, please see the bugs and improvements page and our bug report guide for more details on how to report issues.
Thank you for using and supporting Jami!
By Sébastien Blin, Mehdi Ghayour, Amin Bandali







